Pangea is undergoing a refactoring phase until the end of 2017. An updated model description will be released when this operation is completed.
Overview
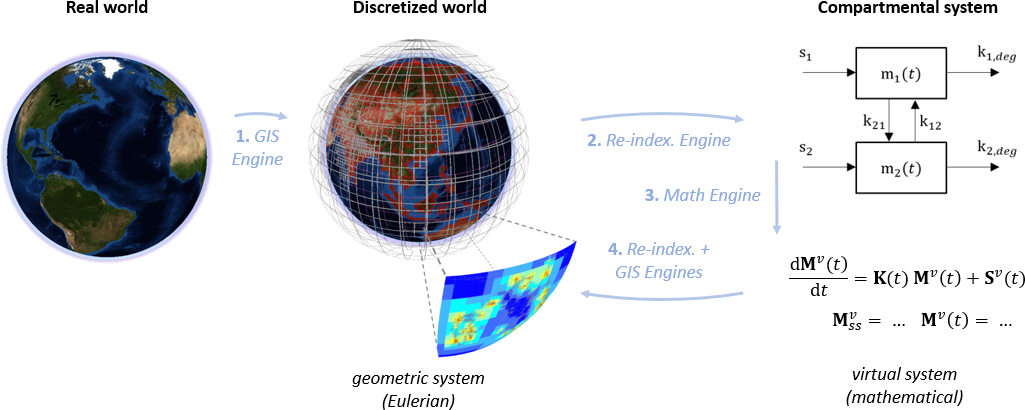
The general flow of operations in Pangea is represented in Fig.1. We start with non-gridded geo-referenced data that characterize the natural system (loosely defined as "the world"). Using its GIS engine [1] and a set of Environmental Models (EMs), Pangea builds a set of grids that cover all relevant media, hence defining the geometrical system, and projects geo-referenced data in this system. Gridded data and geometric and topological parameters are then re-indexed [2] into what we call the virtual system which, in short, is a common indexing schema where all grids and media receive a specific indexing space. Using re-indexed data/parameters and a set of Environmental Processes Models (EPMs), Pangea builds a mathematical compartmental system. This system is solved [3] (for e.g. environmental concentrations at steady-state), further computations are performed (e.g. population exposure), and the solution is re-indexed backward to relevant grids [4] for analysis and visualization.
Sections
The description of Pangea is split into the following sections :
| 1. | Glossary of terms and concepts | Defines majors terms/concepts/features: spatial, multimedia, etc, as well as Pangea-specific terminology. |
| 2. | Extended description | Describes how major grids are built, how multi-scale specifications are expressed. Lists major environmental models (EMs) and environmental processes models (EPMs). |
| 3. | Principal external models and data sets | Lists major external models and data sets relevant to Pangea. |
| 4. | A little bit about the internals | Provides more information about the internals: why MATLAB, structure of the code, etc. |
| 5. | Extra features | Lists a few extra features: wrapper for USEtox 2.0, online databases parsers, etc. |
| 6. | History | Gives the great lines of the history of the developments. |